原文链接:https://towardsdatascience.com/tabnet-deep-neural-network-for-structured-tabular-data-39eb4b27a9e4
在这篇文章中,我将向您介绍一个使用Google的TabNet解决分类问题的示例。
尽管最近针对图像、音频和文本的深度神经网络(DNN)出现了爆炸式增长,但使用良好的结构表格数据的任务似乎在某种程度上被忽略了。
虽然今天的许多数据确实是非结构化的(大约80%),但重要的是要正确认识到,用到行和列的数据中仅有20%仍然代表着巨大的数据量。事实上,在2020年,IBM估计全世界的数据收集量为35 zettabytes(或350亿TB)。
这意味着700000000000000字节的数据需要神经网络模型的关注!
平心而论,正如TabNet的原著所指出的,这是因为当前的集成决策树(DT)变体(XGBoost、LightGBM、CatBoost等)在表格数据方面比DNN有一些优势。
然而,自从TabNet发布以来,所有这些都消失了,它在多个基准数据集中的表现优于基于DT的模型。
弗雷明翰心脏研究 Framingham Heart Study
今天,我将介绍一个如何使用TabNet进行分类任务的示例。该数据集包含弗雷明翰心脏研究的结果,该研究始于1948年,对心血管疾病的风险因素提供了(现在仍然提供)重要的见解。对于那些有兴趣了解更多关于这项研究的人,请查看此链接。
如果您有兴趣了解更多关于TabNet架构的信息,我鼓励您查看我上面链接的原始文件。其他资源包括这个repo,您可以在这里看到原始的TabNet代码。最后,在我们深入讨论之前,您可以使用我的Notebook。
数据
该分析使用的数据由16个变量组成,包括目标变量ANYCHD。下面可以找到每种变量的说明。

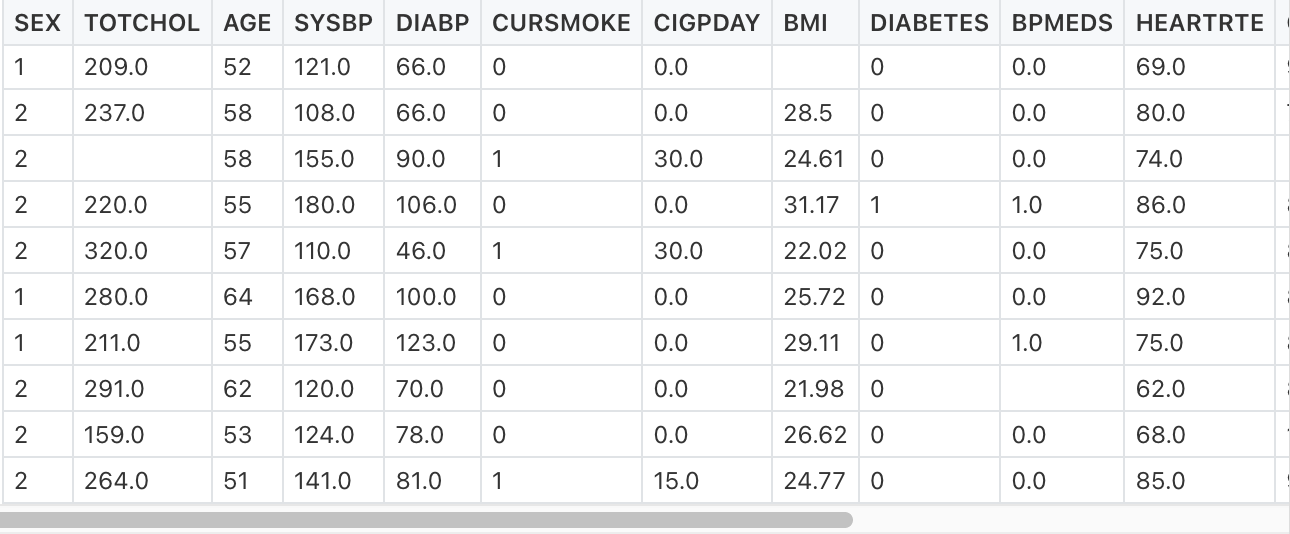
调查缺失值
接下来,我想看看有多少数据丢失了。使用df.isnull().sum()很容易做到这一点,它将告诉我们每个变量缺少多少数据。另一种方法是使用missingno包,它允许我们非常快速地可视化缺失数据之间的关系。
在图1中,用变量表示缺失值(白色)的矩阵表示。这是按行垂直组织的,这允许我们查看缺少的值之间是否存在任何关系。例如,高密度脂蛋白胆固醇(HDLC)和低密度脂蛋白胆固醇(LDLC)的缺失值是相同的,这表明这些值并不是为该数据集中的一部分患者收集的。

我们也可以用不同的方法来观察缺失值之间的关系,如图2所示。在这里,我们更容易看到HDLC和LDLC与TOTCHOL之间的关系。值<1意味着它略小于1。由于这些变量中的al 3是胆固醇的测量值,这表明数据集中的某些患者没有收集胆固醇数据。

插补缺失值
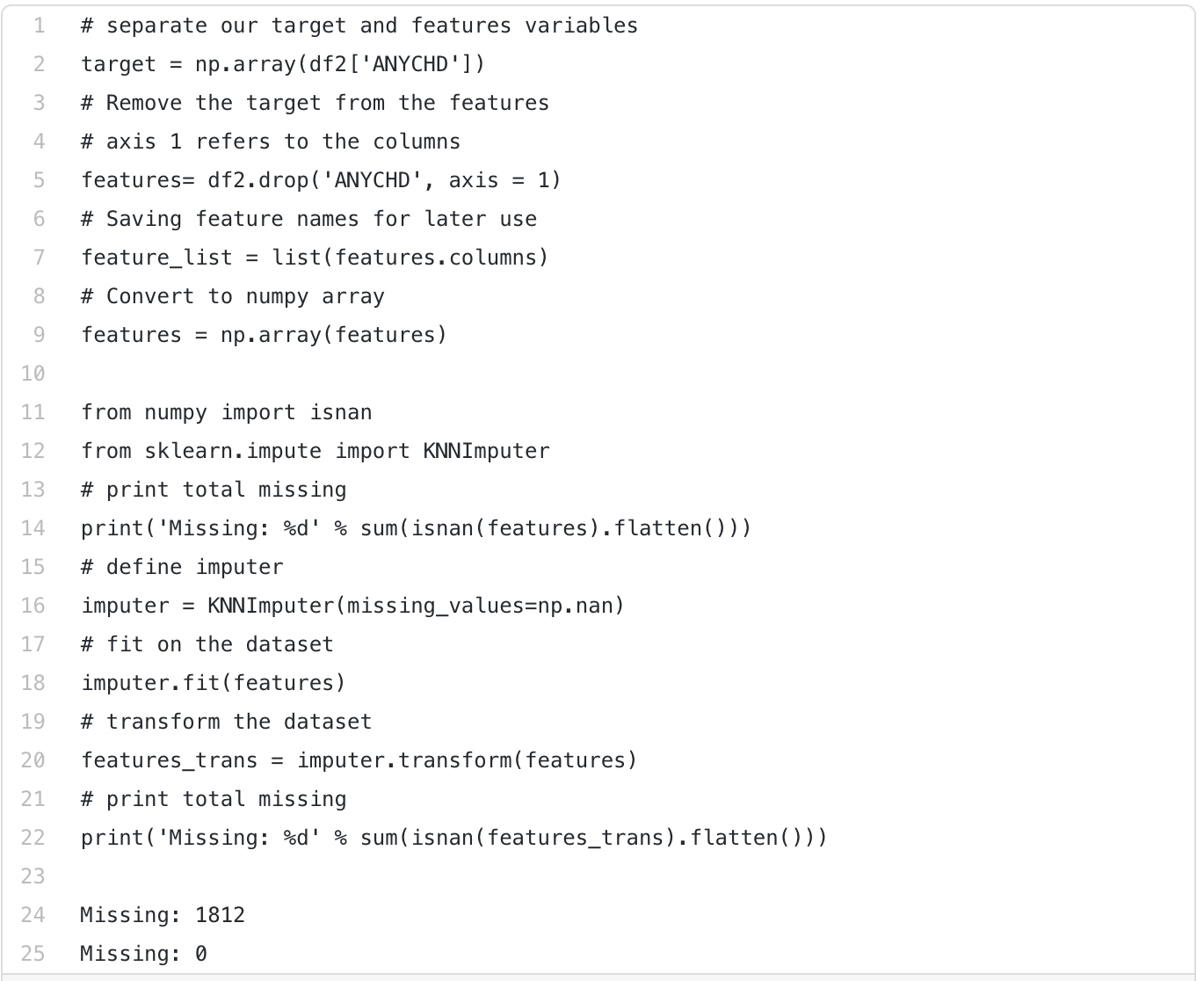
现在我们已经收集了关于缺失值的信息,我们需要决定如何处理它们。根据您的数据,有许多选项,您可以在sklearn的网页上阅读更多有关各种插补算法的信息
我选择了KNN插补器,您可以使用以下代码实现它。总之,在第一块中,我简单地将数据划分为特征和目标。第二个块使用KNN插补器变换特征。从print语句中可以看出,最初估算的缺失值为1812个。
最后一步是分割数据。使用下面的代码,我最初将数据分为70%用于训练集,30%用于验证集。然后,我将验证集分成两个相等的部分,分别用于验证集和测试集。print语句为我们提供了有关拆分后的数据维度

TabNet
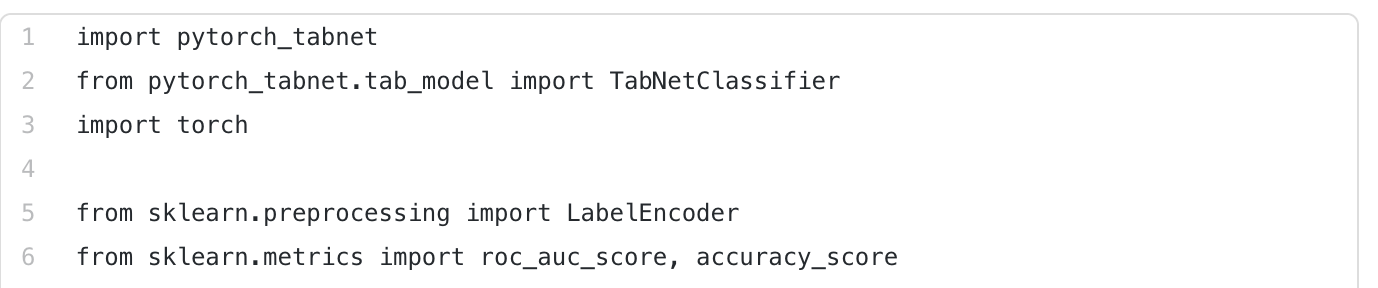
您可以在几行简单的代码中运行TabNet,如下所示。这是TabNet的pytorch实现,因此您必须导入(或安装,如果尚未安装)torch、pytorch_TabNet和您希望使用的模型(二进制分类器、多分类器、回归器)
您还需要某种指标来评估您的模型。以下是可从sklearn获得的列表。我还包括了一个标签编码,以防您的数据与我的数据略有不同。我的分类变量都是二进制整数,但是如果您将分类存储为字符串,那么您将首先使用它(或者一种替代方法,例如one-hot编码)
接下来,我们必须定义我们的模型,您可以在下面的第一段代码中看到。在第一行中,我们定义了优化器Adam。接下来的几行将逐步降低我们的学习率。让我们把它说的话拆开:
- 学习率最初设置为,lr=0.020
- 10个epoch之后,我们将使用0.9的衰减率
- 结果就是在学习率0.9上乘上衰减率0.02,这意味着在第10个epoch它将降低到0.018
在下一段代码中,我们将模型与数据相匹配。基本上,它表示将使用auc(曲线下面积)和精度作为总共1000次迭代(历次)的度量来评估训练集和验证集。
patience参数表示,如果在连续50个epoch后未观察到精度的改进,则模型将停止运行,并加载来自最佳epoch的最佳权重。
256的批量大小是根据TabNet论文中的建议选择的,其中他们建议批量大小最多为总数据的10%。他们还建议虚拟批大小(virtual batch size)小于批大小(batch size),并且可以均匀地划分为批大小。
worker数量保留为零,这意味着将根据需要加载批量大小。增加这个数字会非常消耗内存。
权重可以是0(无采样)或1(自动采样)。最后,如果训练期间未完成,则丢弃最后一批。
需要注意的是,其中许多都是默认参数。您可以在此处查看完整的参数列表。

该分析的结果如图8所示,可以使用下面的代码进行复制。前三个代码块绘制了损失分数、准确性(针对训练集和验证集)和特征重要性(针对测试集)。
最后的模块只计算验证集和测试集的最佳精度,分别为68%和63%。


无监督预训练
TabNet也可以作为无监督模型进行预训练。预训练包括故意屏蔽某些神经元,并通过预测屏蔽值来学习这些神经元与相邻列之间的关系。然后,可以保存所学习的权重,并将其用于监督任务。
让我们看看使用无监督预训练如何影响我们的模型准确性!
虽然类似,但代码有一些差异,因此我在下面将其包括在内。具体来说,您必须导入TabNetPretrainer。您可以在第一段代码中看到,TabNetClassifier被TabNetPretrainer替换。
拟合模型时,请注意最后一行pretraining_ratio,它是预训练期间遮罩的特征的百分比。值为0.8表示80%的特征被遮罩。
下一个代码块是指从TabNet的编码表示生成的重构特征。这些文件将被保存,然后可用于单独的受监督任务。

图9-使用TabNet的无监督表示学习
当对该数据集使用预训练时,验证集和测试集的结果准确率分别为76%和71%。这是一个显著的进步!下面,您可以看到损失分数、训练集(蓝色)和验证集(橙色)的准确性,以及测试集确定的特征重要性。

总结
在这篇文章中,我们介绍了一个如何为分类任务实现TabNet的示例。我们发现,使用TabNet进行无监督预训练显著提高了模型的准确性。
在下面的图11中,我绘制了有监督(左)和无监督(右)模型的特征重要性。有趣的是,无监督的预训练能够提高模型的准确性,同时减少特征的数量。
当我们考虑特征之间的关系时,这是有意义的。例如,使用TabNet进行预训练可以了解到,血压药物(BPMED)、收缩压(SYSBP)和舒张压(DIBP)是相关的。因此,无监督表示学习作为有监督学习任务的高级编码模型,具有更清晰和更可解释的结果。
