Andrew Ng 在今年6月举办了一场名为 Data-Centric AI Competition [1]的机器学习竞赛。和以往的机器学习比赛不一样是,这次比赛里模型训练由主办方提供且是固定不变的。参赛选手需要提供最优的训练数据集(最多10000份数据),让模型产生最优精度。这场比赛背后的用意是,目前机器学习模型已经相对成熟了,而对应的训练数据集的生成优化技术还相对落后。Andrew Ng希望通过这场比赛唤起大家对于数据重要性的认识。
数据清洗
一种比较成功的方案是使用Training Dynamics[2]的技术对训练数据进行分析。它对每一个训练数据定义了3个指标:correctness,confidence和variability。假设我们对模型训练了E个epoch,并记录了每个训练样本在正确标签下的分类概率变化序列(长度为E)。那么:
- Correctness定义为在E次训练中,这个样本被正确分类的次数
- confidence定义为这个序列的均值,
- variability定义为这个序列的方差。
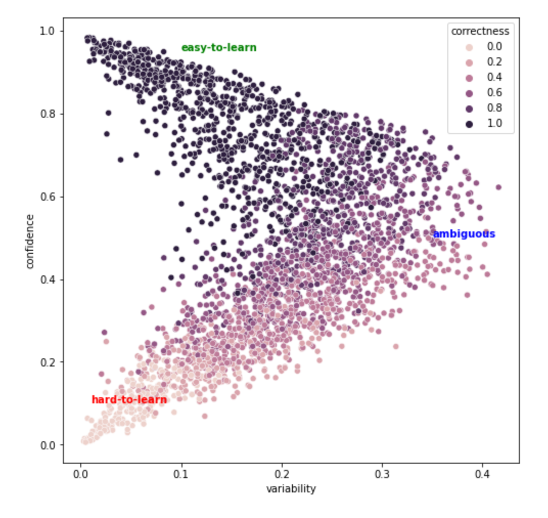
Confidence越接近1说明模型在整个训练过程中对于这个样本的分类都非常确定;variability高则说明这个样本比较模棱两可,但通过一段时间的学习确信度还是有很大变化的。最后样本可以分为三大类别:
- Easy-to-learn:高confidence,低variability。模型非常容易学习的样本
- Ambiguous:中等confidence,高variability。模型比较难判断的样本,但通过学习可以逐步识别
- Hard-to-learn:低confidence,低variability。模型非常难判断,这些可能是噪音数据或者错误标签
参赛队伍accademia_del_cimento 对于Hard-to-learn样本的处理办法是[3]:人工调整标注、清除高噪音样本、或者保持原状。最后根据样本的标签、confidence、variability、correctness进行分层采样,保证了训练样本的均匀覆盖。人工标注可以使用一些工具来辅助进行,例如TornadoAI[4],当然还可以用更成熟的工具比如LabelStudio [5]。
此外,也可以通过多个模型bagging的方法估计不确定性[6]并找到歧义样本。
数据增强
对图片数据进行数据增强是必备手段,可以使用工具如ImageMagick[7]进行数据增强。大量选手使用了python的影像数据增强库 imgaug[8],它可以自动对输入图像应用数十种常用的数据增强转化。对所有数据进行数据增强可能效果并不好,参赛队伍accademia_del_cimento发现只对部分人眼可以轻松识别的数据进行增强会更好[9]
除了传统的图形学手段进行数据增强外,还可以使用生成模型或者对抗手段来生成强化数据。提到的技术包括:Faster AutoAugment[10],Bayesian Data Augmentation[11],RandAugment[12]。其中RandAugment可能效果最好,pytorch也有方便使用的函数 torchvision.transforms.autoaugment[13]来实现对应功能。也有讨论指出这个方式违背了data-centric的初衷,又回到了优化模型的老路。
新数据
有队伍提出可以使用各种不同的字体来合成新数据。
参赛队伍accademia_del_cimento使用分割方法[14]创造了新的数据。例如比赛数据是罗马数字的图片识别,那么罗马数字 VII就可以拆成V, VI, II, I等多个新样本。

甚至有参赛者直接联系亲友创造新数据集[15]
样本挑选
比赛将提交数据限制在了10000个,因此需要挑选最优的样本获得最大的精度。这里可以使用主动学习(Active Learning)[16]的方法挑选样本以取得最多的信息增益(information gain)。
除了主动学习以外,还可以使用传统统计方法来分析决策边界(Decision boundary)和特征空间方差来寻找最优样本组合。例如求解p-Dispersion问题[17],
[1] https://https-deeplearning-ai.github.io/data-centric-comp/
[2] https://arxiv.org/abs/2009.10795
[3] https://www.kaggle.com/steubk/our-journey-into-the-data-centric-ai-competition
[4] https://github.com/slrbl/human-in-the-loop-machine-learning-tool-tornado
[6] https://www.overleaf.com/project/612ea27ecde4c11240644b09
[7] https://medium.com/@walid.daboubi/andrew-ngs-data-centric-ai-competition-how-i-reached-around-82-of-accuracy-on-using-tornadoai-daaad2ccb147
[8] https://imgaug.readthedocs.io/en/latest/index.html
[9] https://www.kaggle.com/steubk/our-journey-into-the-data-centric-ai-competition
[10] https://arxiv.org/abs/1911.06987
[11] https://arxiv.org/abs/1710.10564
[12] https://arxiv.org/abs/1909.13719
[13] https://pytorch.org/vision/master/_modules/torchvision/transforms/autoaugment.html
[14] https://www.kaggle.com/steubk/our-journey-into-the-data-centric-ai-competition
[15] https://community.deeplearning.ai/t/post-competition-idea-sharing/33565/3
[16] B. Settles. Active learning literature survey. Computer Sciences Technical Report 1648, Uni-versity of Wisconsin–Madison, 2009
[17] https://onlinelibrary.wiley.com/doi/10.1111/j.1538-4632.1987.tb00133.x