翻译自:https://arxiv.org/abs/1804.00097,并删减了过于细节的内容。对抗性攻击不仅涉及AI安全性,同时也是优化机器学习模型、避免过拟合的重要手段
0. 引言
机器学习和深度神经网络的最新进展使研究人员能够解决图像、视频、文本分类等多个重要的实际问题。然而,大多数现有的机器学习分类器非常容易受到对抗样本的攻击。一个对抗的例子是输入数据样本经过非常轻微的修改后,可以导致机器学习分类器对其进行错误分类。在许多情况下,这些修改可能非常微小,以至于人类观察者根本没有注意到修改,但分类器仍然会出错。
对抗性样本会带来安全问题,因为它们可能被用于对机器学习系统进行攻击,即使对手无法访问底层模型。此外,人们还发现即使是在物理世界中运行的机器学习系统,也有可能进行对抗性攻击,并通过不准确的传感器感知输入,而不是读取精确的数据。
从长远来看,机器学习和人工智能系统将变得更加强大。类似于对抗性样本的机器学习安全漏洞可用于危害和控制功能强大的AI。因此,对抗性样本的鲁棒性是AI安全问题的一个重要部分。
1. 对抗的例子
对抗性样本是机器学习模型的输入,这些模型经过有意优化,导致模型出错。如果输入样本是自然发生的样本,例如来自ImageNet数据集的照片,我们将其称为“干净样本”。如果一个对手修改了一个例子,意图使它被错误分类,我们称之为“对抗样本”。当然,对手不一定会成功;模型仍然可以正确地对对抗性样本进行分类。我们可以在一组特定的对抗性样本上测量不同模型的准确性或错误率。
2常见攻击场景
可能的对抗性攻击场景可以按照不同的维度进行分类。首先,攻击可根据对手期望的结果类型进行分类:
- 非目标攻击。在这种情况下,对手的目标是使分类器预测任何不正确的标签。具体的错误标签并不重要。
- 有针对性的攻击。在这种情况下,对手的目标是将分类器的预测更改为某个特定的目标类。
其次,攻击场景可以根据对手对模型的了解程度进行分类:
- 白盒。在白盒方案中,对手完全了解模型,包括模型类型、模型架构、所有参数值和可训练权重。
- 带有探测的黑盒。在这种情况下,对手不太了解模型,但可以探测或查询模型,即提供一些输入并观察输出。该场景有许多变体,对手可能知道体系结构,但不知道参数,或者对手甚至可能不知道体系结构,对手可能能够观察每个类的输出概率,或者对手可能只观察最可能的类的选择。
- 无探测的黑盒。在无探测的黑盒场景中,对手对受到攻击的模型的了解非常有限,并且在构建对抗性样本时不允许探测或查询模型。在这种情况下,攻击者必须构建对抗性样本,以愚弄大多数机器学习模型。
第三,可以通过敌方将数据输入模型的方式对攻击进行分类:
- 数字攻击。在这种情况下,对手可以直接访问输入模型的实际数据。换句话说,对手可以选择特定的float32值作为模型的输入。在现实环境中,当攻击者将PNG文件上载到web服务,并故意将文件设计为不正确读取时,可能会发生这种情况。例如,使用图像文件的对抗性干扰来逃避垃圾邮件检测器。
- 物理攻击。在物理世界中发生攻击的情况下,对手无法直接访问提供给模型的数字表示。取而代之的是,该模型由诸如照相机或微型手机等传感器获得的输入反馈。对手能够将物体放置在摄像机看到的物理环境中,或产生麦克风听到的声音。传感器获得的精确数字表示将根据摄像机角度、到麦克风的距离、环境中的环境光或声音等因素而变化。这意味着攻击者对提供给机器学习模型的输入的控制不太精确。
3. 攻击方法
3.1白盒数字攻击
L-BFGS
L-BFGS 是神经网络的中间多个样本的首要方法之一。该方法的思想是解决以下优化问题:
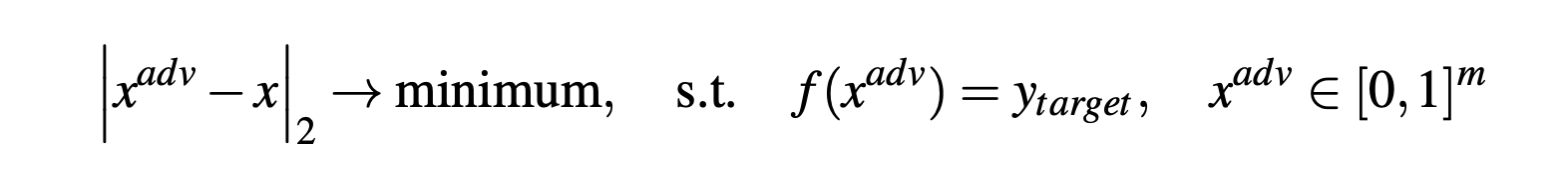
作者使用L-BFGS方法来求解上述优化问题,因此该攻击的名称也称为L-BFGS。
这种方法的一个主要缺点是速度很慢。方法不是为了抵消防御措施,例如减少用于存储每个像素的位数。相反,该方法旨在找到可能的最小攻击扰动。这意味着该方法有时可能仅通过降低图像质量(例如,通过舍入到每个像素的8位表示)而失败。
快速梯度符号法(FGSM)
FGSM是为了验证仅使用目标模型的线性近似即可找到对抗性样本的想法。FGSM通过线性化损耗函数的邻域来实现攻击,并使用以下闭合形式方程找到线性化函数的精确最大值:
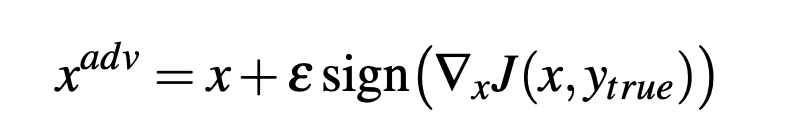
迭代攻击
L-BFGS攻击具有较高的成功率和计算成本。FGSM攻击具有较低的成功率(特别是当防御者有准备时)和较低的计算成本。通过运行迭代优化算法可以实现一个很好的折衷,迭代优化算法专门用于在少量(例如40次)迭代后快速获得解决方案。
快速设计优化算法的一种策略是采用FGSM(通常可以在一个非常大的步长中获得可接受的解决方案),并以较小的步长运行几个步长。由于FGSM的每一步都被设计为一直走到围绕该步起点的一个小标准球的边缘,因此该方法即使在梯度很小的情况下也能取得快速的进展。据观察,只要迭代次数足够,这种攻击几乎总能成功命中目标类。
对抗性转换网络(ATN)
另一种方法是训练生成模型来制作对抗性样本。该模型以一个干净的图像作为输入,并生成相应的对抗图像。这种方法的一个优点是,如果生成模型本身设计得很小,ATN可以比显式优化算法更快地生成对抗性样本。从理论上讲,如果ATN被设计为使用较少的计算来在目标模型上运行反向传播,那么这种方法甚至可以比FGSM更快(ATN当然需要额外的训练时间,但一旦训练完成,就可以以低成本生成无限数量的样本)
攻击非微分系统
所有攻击都需要计算受攻击模型的梯度,以便制作对抗性样本。然而,这可能并不总是可能的,例如,若模型包含不可微操作。在这种情况下,对手可以训练一个替代模型,并利用对抗样本的可转移性对不可微系统进行攻击,类似于黑箱攻击,如下所述。
3.2黑盒攻击
据观察,对抗性样本在不同的模型之间具有普遍性。换句话说,愚弄一个模型的对抗性例子中有相当一部分能够愚弄另一个模型。此属性称为“可转移性”,用于在黑盒场景中制作对抗性样本。根据源模型、目标模型、数据集和其他因素的不同,可转移对抗性样本的实际数量可能从几个百分比到几乎100%不等。黑盒场景中的攻击者可以在与目标模型相同的数据集上训练自己的模型,甚至可以在来自同一分布的另一个数据集上训练自己的模型。对抗模型的对抗样本很有可能愚弄未知目标模型。
也可以有意识地设计模型来系统地导致高转移性,而不是依靠运气来实现转移。
如果攻击者不在完整的黑盒场景中,但允许探测,则探测可用于训练攻击者自己的目标模型副本,称为“替代品”。这种方法非常有效,因为作为探测器发送的输入样本不必是实际的训练样本;相反,它们可以是攻击者选择的输入点,以查明目标模型决策边界的确切位置。因此,攻击者的模型不仅被训练成一个好的分类器,而且被训练成对目标模型的细节进行反向工程,因此这两个模型被系统地驱动,以获得大量的参数转移。
在攻击者无法进行探测的完全黑盒场景中,提高转移率的一种策略是使用多个模型的集合作为对抗性样本的源模型。其基本思想是,如果一个通用样本愚弄了集合中的每个模型,那么它更有可能推广和愚弄其他模型。
最后,在可以探测的黑盒场景中,可以只运行优化算法,而不使用梯度直接攻击目标模型。生成单个对抗性样本所需的时间通常远高于使用替代品时所需的时间,但如果只需要少量的对抗性样本,则这些方法可能具有优势,因为它们没有训练替代品的高初始固定成本。
4 防御技术
目前还没有一种针对对抗性例子的防御方法是完全令人满意的。这仍然是一个快速发展的研究领域。这里概述了迄今为止提出的(尚未完全成功的防御方法)。
图像预处理
由于许多方法产生的对抗性干扰在人类观察者看来像高频噪声,多位作者建议使用图像预处理和去噪作为对抗性测试的潜在防御。所提出的预处理技术有很大的不同,如进行JPEG压缩或应用中值滤波并降低输入数据的精度。虽然此类防御措施可以很好地抵御某些攻击,但在白盒案例中,此类防御措施被证明是失败的,因为攻击者知道防御措施。在黑匣子的情况下,这种防守在实践中是有效的。
许多防御措施,无论有意还是无意,都属于“梯度掩蔽”的范畴。大多数白盒攻击通过计算模型的梯度来进行操作,因此,如果无法计算有用的梯度,则会失败。梯度掩蔽包括通过改变模型使其不可微或使其在大多数地方具有零梯度,或使梯度点远离决策边界,从而使梯度无效。本质上,梯度掩蔽意味着在不实际移动类决策边界的情况下打破优化器。由于类决策边界大致相同,基于梯度掩蔽的防御非常容易受到黑盒转移攻击的影响。一些防御策略是专门设计来执行梯度掩蔽的。其他防御,如许多形式的对抗性训练,并不是以梯度掩蔽为目标而设计的,但在实践中似乎经常变成梯度掩蔽。
检测对抗性样本
许多防御措施的基础是检测对抗性样本,并在有篡改迹象时拒绝对输入进行分类。只要攻击者不知道检测器或者攻击不够强,这种方法就有用。否则,攻击者可以发起攻击,同时欺骗检测器认为对抗输入是合法输入,并欺骗分类器进行错误分类。
一些防御措施虽然起作用,但这样做的代价是严重降低干净样本的准确性。例如,浅层RBF网络对小型数据集(如MNIST)上的对抗性样本具有高度鲁棒性,但对于干净的MNIST,其精确度比深层神经网络差得多。深度RBF网络可能对对抗性样本具有鲁棒性,并且对干净数据具有精确性,但据我们所知,还没有人成功地训练过一个深度RBF网络。
Capsule网络对Small-NORB数据集上的白盒攻击具有鲁棒性,但尚未对对抗样本文献中更常用的其他数据集进行评估。
对抗性训练
当前研究论文中最流行的防御可能是对抗性训练。其想法是将对抗性样本注入训练过程,并根据对抗性样本或干净样本与对抗性样本的混合对模型进行训练。该方法已成功应用于大型数据集,并且可以通过使用离散向量码表示(discrete vector code representations)而不是输入的实数表示来提高效率。
对抗式训练的一个主要缺点是,它往往过度适应训练时使用的特定攻击。至少在小型数据集上,通过在启动攻击的优化器之前添加噪声,已经克服了这一问题。
对抗式训练的另一个关键缺点是,它往往会在无意中学习进行梯度掩蔽,而不是实际移动决策边界。这在很大程度上可以通过训练从多个模型集合中提取的对抗性样本来克服。
另一个缺点是,它往往过度适合用于生成对抗性样本的特定约束区域,训练用于防御的对抗性样本的可能无法抵抗基于对背景像素的大量修改的对抗性样本,而这些新的对抗性样本对人类观察者而言毫无差异。