本文翻译自:https://towardsdatascience.com/bias-and-algorithmic-fairness-10f0805edc2b
随着数据科学沿着炒作周期发展,并作为一种业务功能日趋成熟,该学科面临的挑战也随之而生。
过去几年,数据科学的问题陈述从“我们浪费80%的时间准备数据”到“生产部署是数据科学最困难的部分”再到“缺乏可测量的业务影响”。
但是,随着商业数据科学作为一种商业功能的整合,并克服了早期的问题,我们面临着新的具有挑战性的问题:
- 数据伦理,
- 模型可解释性和问责制,
- 算法公平性。
虽然数据科学家和商业领袖可以在很大程度上依赖技术进步来解决第一轮数据科学初期的问题,但仅仅指望技术来解决这些新挑战是错误的。
我个人承认,我对如何使用数据太天真了,而且在如何处理数据方面受到了相当大的误导。我不能一个人承认吗?
这将不是一个学术上和法律上全面的讨论这个话题,而是我个人的经验。为了更详细地了解人工智能中公平和责任的法律含义,我建议遵循Sandra Wachter博士的观点,阅读“合理推断的权利:重新思考大数据和人工智能时代的数据保护法“A Right to Reasonable Inferences: Re-thinking Data Protection Law in the Age of Big Data and AI”
黑匣子没了?
我对数据科学的作用的理解遇到了第一个挑战,那就是逐渐消退的宣传不再能成为机器学习黑匣子的借口。模型的可解释性从一个意想不到的方向进入了我的思维:我的利益相关者。利益相关者比大多数数据科学家更关心模型的详细工作!这并不意味着我没有意识到黑匣子,但我从风险缓解的心态来处理它。(交叉验证、对模型输入和输出的广泛测试、日志记录和监视、对模型使用的限制、大量的善意、快速失败并重试……)
我做过,但仍然把数据科学视为生产中的实验。但是,虽然我以前认为黑匣子只需要保障措施来确保预测有意义,但我现在明白了为什么需要一些模型的可解释性,不仅是为了问责,而且是为了对预测有意义有实际的信心。为了限制ML黑盒的人为愚蠢,我们需要模型的可解释性来定义何时对表现良好的输入数据进行评分是安全的,何时最好不进行评分,即以前看不到的输入数据。
ML非常适合和强大的决策空间插值。不幸的是,使用ML将决策推断到新的和看不见的数据的不安全区域太容易和诱人了,这从来不是模型训练和模型验证的一部分。
虽然ML黑匣子在我的日常工作中只是一个灰色的盒子,但模型的可解释性为我提供了必要的信心,并提高了我们抑制人为愚蠢的能力,使我们的模型保持在众所周知的安全保障范围内。这意味着有时最好不要提供分数。
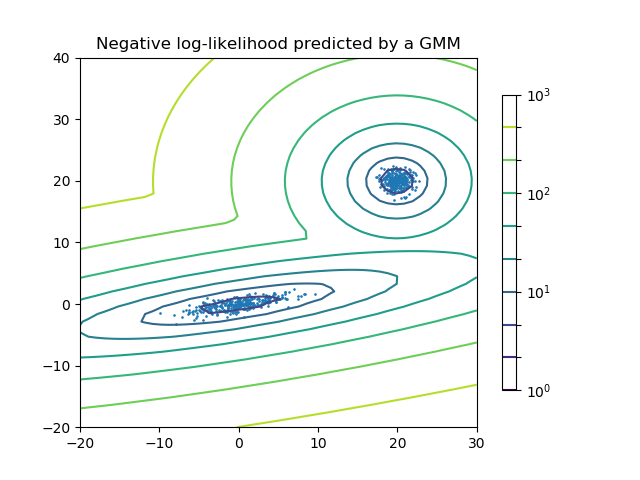
实现这一点的一个非常简单但非常有效的方法是,在训练数据上拟合一个独立的高斯混合模型,以确定决策空间的置信边界。如果您的模型输入不在GMM的置信范围内,就不要返回模型输出。
目前,我希望,一方面,数据科学领域的科技进步将进一步解决模型的可解释性问题,另一方面,作为一名数据科学家,我很乐意承担模型可解释性的责任。
偏见
虽然模型的可解释性是商业数据科学职能部门本身的责任,但数据伦理和算法公平性不能仅由数据科学部门拥有!为什么?因为公平模型是对精确模型的一种权衡,保持这种平衡意味着它将成为高级领导的责任。希望当你在文章的结尾看到总结的时候,这会变得更有意义。
现实情况是,任何由人类行为产生或衍生的数据点,都会在本质上受到我们人类偏见似乎无穷无尽的列表的污染。只是想说几句:
群体内的偏袒和群体外的消极:偏好我们自己的社会群体中的人,而不是倾向于惩罚或给群体外的人施加负担。偏见在偏见和歧视中起着重要作用。
基本归因错误:当我们倾向于将某人的行为归因于其性格的内在品质而不是情境背景时。
消极偏见:当我们强调消极经验多于积极经验时,这对社会判断和印象形成有重要影响。
刻板印象:当我们期望一个群体中的某个成员具有某些特征,而没有关于这个人的实际信息时。
随波逐流效应:当我们做某事或相信某事时,因为许多人都这样做。
偏见盲点:我们倾向于看不到自己的个人偏见。
我们所有的数据都是有偏见的,因为世界是有偏见的。
修正世界上的偏见超出了数据科学家的工作规范。然而,不使用ML模型来强化现有的偏见是一个数学问题,它很快就从单纯的道德义务转变为现代数据科学家的工作要求。
解决数据科学中的偏见是一个极其复杂的话题,最重要的是没有通用的解决方案或银弹。在任何一位数据科学家致力于减少偏见之前,我们需要通过查阅以下公平性树,在我们的业务问题背景下定义公平性:
根据您的业务问题阅读公平树并非易事。作为一个例子(改编自这里),假设你想设计一些ML系统来处理抵押贷款申请,只有一小部分的申请是由女性提出的。
- 群体无意识选择:我们在申请过程中完全忽略了性别信息。因为贷款人可以授予的批准数量有限,所以根据客观的、不分性别的标准,这些批准只能授予最合格的个人。但是,删除性别和性别代理信息并不能解决历史偏见,而且通常不是一个非常有效的过程来减轻偏见,我们将在下面的美国人口普查数据的工作示例中看到这一点。
- 调整后的群体阈值:由于历史偏见使女性看起来不如男性值得贷款,例如工作经历和托儿责任,我们按群体使用不同的批准阈值。
- 人口均等:批准率应反映各组申请的百分比。但这并没有考虑到抵押贷款违约的风险。
- 平等机会:同样比例的有贷款价值的男女获得了抵押贷款。这似乎符合抵押贷款机构的业务目标,而且似乎是公平的。“有资格获得理想结果的个人应该有平等的机会被正确分类为这种结果。”(莫里茨·哈特)
- 精确平等:不发放贷款会对个人产生非常负面的影响。在机会均等的情况下,两个群体都有真正的正均等。但是如果模型错误的是女性不偿还贷款的频率是男性的两倍(假阴性),那么模型会拒绝接受贷款的女性是男性的两倍。因此,应该调整模型,使模型错误的次数在两组的批准和拒绝总数中所占的百分比相同。精度奇偶校验也是公平树的建议(错误>惩罚>小干预量)。
算法公平
确定公平的适当定义只是第一步。下一步是为偏差选择合适的缓解策略。同样,减轻偏见是一个复杂的话题,同样,没有通用的方法或银弹。下图显示了IBM的AIF360工具包中缓解策略和现有实现的3个主要类别:
IBM的trusted AI是了解更多细节的绝佳资源:https://www.research.ibm.com/artificial-intelligence/trusted-ai/
使用TensorFlow 2.0进行对抗性去偏见——一个例子
为了突出偏颇数据的挑战以及数据科学家能做些什么,我们来看看1994年美国人口普查收入数据集。
目标是建立一个分类模型来预测一个人的年收入是否超过5万美元。这个问题从根本上讲是有偏见的(性别工资差距、歧视等),数据集包括敏感数据:种族和性别。因此,我们从模型输入中删除这些敏感数据,试图构建一个不分组的分类器。下图显示了我们用于解决问题的神经网络体系结构:
该体系结构使用一个编码器神经网络来创建一个共享的数据嵌入,它为3个分类神经网络提供数据,这些神经网络的目标是预测个人的工资、性别和种族。
class AdversarialModel(tf.keras.Model):
def init(
self,
tf_feature_columns,
encoder_units, decoder_units, model_head_names
):
super(AdversarialModel, self).init()
self.output_model_names = model_head_names
self.encoder_model = tf.keras.Sequential(
[
tf.keras.layers.DenseFeatures(tf_feature_columns),
tf.keras.layers.Dense(units=encoder_units, activation=tf.nn.leaky_relu),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(units=encoder_units, activation=tf.nn.leaky_relu)
], name="encoder"
)
for model_name in self.output_model_names:
model = tf.keras.Sequential(
[
tf.keras.layers.InputLayer(input_shape=(encoder_units,)),
tf.keras.layers.Dense(units=decoder_units,
activation=tf.nn.leaky_relu),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(units=decoder_units, activation=tf.nn.leaky_relu),
tf.keras.layers.Dense(units=1, activation='linear', name=model_name),
], name=model_name
)
setattr(self, model_name, model)
def call(self, x):
x_enc = self.encoder_model(x)
return list(
map(
lambda model_name: getattr(self, model_name)(x_enc), self.output_model_names
)
)
# Create categorical embedding feature columns
CATEGORICAL_COLUMNS = ['workclass', 'education', 'marital-status', 'occupation','relationship', 'native-country']
NUMERIC_COLUMNS = ['age', 'education-num', 'capital-gain', 'capital-loss', 'hours-per-week']
tf_feature_columns = []
for feature_name in CATEGORICAL_COLUMNS:
vocab = df[feature_name].unique()
tf_feature_columns.append(
tf.feature_column.embedding_column(
categorical_column=tf.feature_column.categorical_column_with_vocabulary_list(feature_name, vocab),
dimension=int(max([2, len(vocab)**0.25]))
)
)
for feature_name in NUMERIC_COLUMNS:
tf_feature_columns.append(tf.feature_column.numeric_column(feature_name, dtype=tf.float32))
model = AdversarialModel(tf_feature_columns, 128, 64, ["salary", "sex", "race"])
model.summary()
"""
Model: "adversarial_model"
Layer (type) Output Shape Param #
encoder (Sequential) multiple 19006
salary (Sequential) (None, 1) 12481
sex (Sequential) (None, 1) 12481
race (Sequential) (None, 1) 12481
Total params: 56,449
Trainable params: 56,449
Non-trainable params: 0
"""在第一轮中,我们不使用任何对抗性梯度,而是将模型训练为标准的多类分类器,以观察我们尝试的群体无意识是多么成功。下表显示了20轮训练后的模型性能:
显然,删除敏感数据并不是让我们的模型抹去偏见。从剩下的数据中我们可以很好地预测性别和种族。这一点也不奇怪,因为我们的问题也有历史偏见,敏感数据与所有其他特征相关,例如教育、职业选择等。
我们将使用对抗性神经网络从共享数据嵌入中删除任何种族或性别相关信息。TensorFlow 2.0的自定义训练循环对NN头进行4个时期的训练,以适应当前的共享数据嵌入,然后使用性别和种族分类器的负梯度对编码器进行对抗性训练:
def train_one_batch(model, features, targets, label_imbalance, loss_weights, model_name, encoder_loss_signs):
with tf.GradientTape() as tape:
logits = model(features)
y_ = tf.math.sigmoid(logits)
nn_head_losses = list(
map(
lambda i: tf.nn.weighted_cross_entropy_with_logits(
labels=tf.expand_dims(targets[i], 1),
logits=logits[i],
pos_weight=np.array([label_imbalance[i], 1.0/label_imbalance[i]])
), range(len(model.output_model_names))
)
)
encoder_loss = tf.add_n(
list(
map(
lambda x: x[0]x[1]x[2], list(zip(encoder_loss_signs, loss_weights, nn_head_losses))
)
)
)
if model_name == "encoder":
grad = tape.gradient(encoder_loss, model.trainable_variables)
else:
model_index = model.output_model_names.index(model_name)
grad = tape.gradient(nn_head_losses[model_index], model.trainable_variables)
return y_, encoder_loss, grad
Assemble a TF dataset
sensitives_sex = (df_train['sex'] == 'Female').astype(dtype=np.float32)
sensitives_race = (df_train['race'] != 'White').astype(np.float32)
label = (df_train['label'] == '>50K').astype(dtype=np.float32)
BATCH_SIZE = 100
ds_train = tf.data.Dataset.from_tensor_slices(
(
(df_train.loc[:,CATEGORICAL_COLUMNS+NUMERIC_COLUMNS]).to_dict("list"),
(label.values, sensitives_sex.values, sensitives_race.values)
)
).batch(BATCH_SIZE)
epochs = 100
labels = ['salary','sex', 'race']
loss_weights = [0.5, 0.25, 0.25] # The weights of the NN heads in the loss of the Encoder
encoder_loss_signs = [1.0, -1.0, -1.0] # Negative adversarial gradients for sex and race
optimizer = tf.keras.optimizers.Adam(learning_rate=1e-5)
Our manual training loop
for epoch in range(epochs):
accuracy = dict(
map(
lambda x: (x, tf.keras.metrics.BinaryAccuracy(threshold=0.5)), labels
)
)
epoch_loss_avg = tf.keras.metrics.Mean()
is_adversarial_emb_training = epoch % 5 == 0
for features, targets in ds_train:
label_imbalance = list(map(lambda x: (x.numpy() == 1).sum() / len(x.numpy()), targets))
if is_adversarial_emb_training:
model.encoder_model.trainable = True
for output_model_name in model.output_model_names:
getattr(model, output_model_name).trainable = False
, loss, grad = train_one_batch(
model, features, targets, label_imbalance,
loss_weights, "encoder", encoder_loss_signs)
optimizer.apply_gradients(zip(grad, model.trainable_variables))
model.encoder_model.trainable = False
for train_output_model_index, train_output_model_name in enumerate(model.output_model_names):
for output_model_name in model.output_model_names:
if output_model_name == train_output_model_name:
getattr(model, output_model_name).trainable = True
else:
getattr(model, output_model_name).trainable = False
y, loss, grad = train_one_batch(
model, features, targets, label_imbalance,
loss_weights, train_output_model_name, encoder_loss_signs
)
optimizer.apply_gradients(zip(grad, model.trainable_variables))
accuracy[train_output_model_name](
targets[train_output_model_index],
y_[train_output_model_index],
sample_weight=tf.expand_dims(
targets[train_output_model_index](
(
(1.0 - label_imbalance[train_output_model_index]) / label_imbalance[train_output_model_index]
) -1.0 ) + 1.0, 1
)
)
epoch_loss_avg(loss)
print(
"{}Epoch {:03d}: Loss: {:.3f}".format(
"" if is_adversarial_emb_training else " ",
epoch,
epoch_loss_avg.result()
),
*list(map(lambda x: "{}_accuracy: {:.3f}".format(x[0], x[1].result()), accuracy.items()))
)
"""
*Epoch 000: Loss: -1.209 salary_accuracy: 0.806 sex_accuracy: 0.612 race_accuracy: 0.726
Epoch 001: Loss: -0.499 salary_accuracy: 0.812 sex_accuracy: 0.644 race_accuracy: 0.643
…
"""虽然3个神经网络头的目标是将个人分类到尽可能高的精度,但编码器的目标是提高工资分类器的精度,同时消除性别和种族的可预测性。
更为复杂的是,我们还必须解决公平定义中数据集中不同群体的严重失衡问题。不平衡数据是现实世界数据集的一个常见挑战,我们解决了模型损失和精度计算中的不平衡问题。这就是为什么我们使用自定义权重来对应数据的不均匀性,并使用 tf.nn.weighted_cross_entropy_with_logits()在神经网络输出层用线性激活函数来检索logits。
模型对抗性训练的结果如下:
我们成功地从编码器产生的共享数据嵌入中去除了种族和性别的可预测性。但是,由于全球存在偏见,薪资分类的准确性也受到了严重影响,特别是高收入者的可预测性。我想没有什么意外。
小结与数据伦理
数据科学有能力改变企业,在降低B2B的风险和成本,提供创新的B2C新产品方面做得很好,但数据科学应用也有很大的责任。我们必须不惜一切代价避免数据科学以一种不可解释和不可解释的方式自动强化偏见。
这篇文章有希望说明一些要点:
- 公平和减少偏见是一个复杂的话题,我当然不是专家
- 在我们生活的这个有偏见的世界里,减少偏见会影响模型的准确性,我们会看到一个准确性与公平的权衡困境。
- 从模型输入中删除敏感数据不会使模型组不知道或不公平。
- 我们必须首先记录敏感数据,才能将其用于我们模型的对抗性训练。这对于解释数据保护和数据伦理“使用与用户需求相称的数据”具有重要意义。数据保护法对个人数据非常明确,对个人可识别的敏感数据更为严格。不记录这样的数据似乎是最容易和最安全的选择,以遵守和表面上似乎促进公平通过群体的不知情。但我们在上面的美国人口普查数据例子中看到,这是错误的!它可能符合数据保护法,但并没有实现公平。虽然数据保护促使企业不收集敏感数据,但合乎道德的数据使用实际上有理由转而投资于安全和合规的敏感数据收集。
正是在这一点上,高级业务主管必须承担以下责任:
- 权衡模型的准确性与公平性,这是一个影响盈利的决策
- 是要避免收集敏感数据以实现理想的数据保护,还是收集敏感信息以便在公平的基于借方的模型中以合乎道德的方式使用数据,这是一个具有风险和成本影响的决策(例如数据泄露、安全的数据基础设施等)